
扫描手机二维码
开通时间:..
最后更新时间:..
 赞
赞
的个人主页 http://faculty.dlut.edu.cn/yexinchen/zh_CN/index.htm
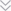
Unsupervised Monocular Depth Estimation via Recursive Stereo Distillation
Xinchen Ye, Xin Fan*, Mingliang Zhang, Wei Zhong, Rui Xu
Dalian University of Technology
* Corresponding author
Code: https://github.com/goldenwoman/Recursive_Stereo_Disill
Paper: ![]() bare_jrnl.pdf
bare_jrnl.pdf
Abstract
Existing unsupervised monocular depth estimation methods resort to stereo image pairs instead of ground-truth depth maps as supervision to predict scene depth. Constrained by the type of monocular input in testing phase, they fail to fully exploit the stereo information through the network during training, leading to the unsatisfactory performance of depth estimation. Therefore, we propose a novel architecture which consists of a monocular network (Mono-Net) that infers depth maps from monocular inputs, and a stereo network (Stereo-Net) that further excavates the stereo information by taking stereo pairs as input. During training, the sophisticated Stereo-Net guides the learning of Mono-Net and devotes to enhance the performance of Mono-Net without changing its network structure and increasing its computational burden. Thus, monocular depth estimation with superior performance and fast runtime can be achieved in testing phase by only using the lightweight Mono-Net. For the proposed framework, our core idea lies in: 1) how to design the Stereo-Net so that it can accurately estimate depth maps by fully exploiting the stereo information; 2) how to use the sophisticated Stereo-Net to improve the performance of Mono-Net. To this end, we propose a recursive estimation and refinement strategy for Stereo-Net to boost its performance of depth estimation. Meanwhile, a multi-space knowledge distillation scheme is designed to help Mono-Net amalgamate the knowledge and master the expertise from Stereo-Net in a multi-scale fashion. Experiments demonstrate that our method achieves the superior performance of monocular depth estimation in comparison with other state-of-the-art methods.
Method

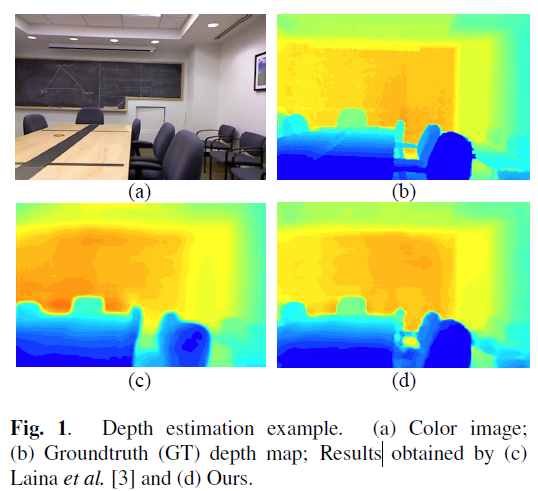
Figure 1. Network overview. It includes a Mono-Net M and a Stereo-Net S, where M is a lightweight network that takes a single image as input, while S takes stereo images pair as input. S contains a recursive estimation strategy and a feature-driven adaptive refinement module to further improve the accuracy of depth estimation. The multi-space knowledge distillation scheme is designed to distill knowledge from S and squeeze into M.

Figure 2. Structures of Mono-Net M, Stereo-Net S, and the multi-space knowledge distillation scheme. We propose to cascade the feature-driven adaptive refinement module with S and update network weights in a recursive manner. The multi-space knowledge distillation scheme is designed to transfer knowledge from S to M in the aspects of output space, feature space and long-range dependencies based on multi-scale feature extraction.
Results

Figure 3. Qualitative comparison with different methods on KITTI dataset. (a) Color image, (b) Ground-truth, (c) Xu et al., (d) Godard et al., (e) Zhan et al., (f) Pilzer et al., (g) Wong et al., (h) Ours.
Citation
Xinchen Ye, Xin Fan*, Mingliang Zhang, Wei Zhong, Rui Xu, Unsupervised Monocular Depth Estimation via
Recursive Stereo Distillation, IEEE Trans. Image Processing, accepted, 2021.
@article{Ye2021tip,
author = {Xinchen Ye, Xin Fan, Mingliang Zhang, Wei Zhong, Rui Xu},
title = {Unsupervised Monocular Depth Estimation via Recursive Stereo Distillation},
booktitle = {IEEE Trans. Image Processing (TIP)},
year={2021}, volume={0}, pages={0-0},
}
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer
for Single Depth Super-Resolution
Baoli Sun1, Xinchen Ye*1, Baopu Li2, Haojie Li1, Zhihui Wang1, Rui Xu1
1 Dalian University of Technology, 2 Baidu Research, USA
* Corresponding author
Code: https://github.com/Sunbaoli/dsr-distillation
Paper: ![]() Paper Download.pdf
Paper Download.pdf
Abstract
Existing color-guided depth super-resolution (DSR) approaches require paired RGB-D data as training samples where the RGB image is used as structural guidance to recover the degraded depth map due to their geometrical similarity. However, the paired data may be limited or expensive to be collected in actual testing environment. Therefore, we explore for the first time to learn the cross-modality knowledge at training stage, where both RGB and depth modalities are available, but test on the target dataset, where only single depth modality exists. Our key idea is to distill the knowledge of scene structural guidance from RGB modality to the single DSR task without changing its network architecture. Specifically, we construct an auxiliary depth estimation (DE) task that takes an RGB image as input to estimate a depth map, and train both DSR task and DE task collaboratively to boost the performance of DSR. Upon this, a cross-task interaction module is proposed to realize bilateral cross-task knowledge transfer. First, we design a cross-task distillation scheme that encourages DSR and DE networks to learn from each other in a teacher-student role-exchanging fashion. Then, we advance a structure prediction (SP) task that provides extra structure regularization to help both DSR and DE networks learn more informative structure representations for depth recovery. Extensive experiments demonstrate that our scheme achieves superior performance in comparison with other DSR methods.
Method

Figure 1. Color-guided DSR paradigms. (a) Joint filtering, (b) Multi-scale feature aggregation, (c) Our cross-task interaction mechanism to distill knowledge from RGB image to DSR task without changing its network architecture.

Figure 2. Illustration of our proposed framework, which consists of DSRNet, DENet, and the middle cross-task interaction module. In testing phase, DSRNet is the final choice to
predict HR depth map from only LR depth map without the help of color image.
Result

Figure 3. Visual comparison of x8 DSR results on Art and Dolls in Middlebury.

Figure 4. Visual comparison of x16 DSR results on NYU v2 dataset.
Citation
Baoli Sun, Xinchen Ye*, Baopu Li, Haojie Li, Zhihui Wang, Rui Xu, Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution, IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
@article{Sun2021cvpr,
author = {Baoli Sun, Xinchen Ye, Baopu Li, Haojie Li, Zhihui Wang, Rui Xu},
title = { Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution},
booktitle = {Proc. Computer Vision and Pattern Recognition (CVPR)},
year={2021},
}
PMBANet: Progressive Multi-Branch Aggregation Network for Scene Depth Super-Resolution
Xinchen Ye1*, Baoli Sun1, Zhihui Wang*1, Jingyu Yang2, Rui Xu1, Haojie Li1, Baopu Li3
1 Dalian University of Technology, 2 Tianjin University, 3 Baidu Research, USA
* Corresponding author
Code: https://github.com/Sunbaoli/PMBANet_DSR
Paper: ![]() pmba-net.pdf
pmba-net.pdf
Abstract
Depth map super-resolution is an ill-posed inverse problem with many challenges. First, depth boundaries are generally hard to reconstruct particularly at large magnification factors. Second, depth regions on fine structures and tiny objects in the scene are destroyed seriously by downsampling degradation. To tackle these difficulties, we propose a progressive multi-branch aggregation network (PMBANet), which consists of stacked MBA blocks to fully address the above problems and progressively recover the degraded depth map. Specifically, each MBA block has multiple parallel branches: 1) The reconstruction branch is proposed based on the designed attention-based error feed-forward/-back modules, which iteratively exploits and compensates the downsampling errors to refine the depth map by imposing the attention mechanism on the module to gradually highlight the informative features at depth boundaries. 2) We formulate a separate guidance branch as prior knowledge to help to recover the depth details, in which the multi-scale branch is to learn a multi-scale representation that pays close attention at objects of different scales, while the color branch regularizes the depth map by using auxiliary color information. Then, a fusion block is introduced to adaptively fuse and select the discriminative features from all the branches. The design methodology of our whole network is well-founded, and extensive experiments on benchmark datasets demonstrate that our method achieves superior performance in comparison with the state-of-the-art methods.
Method

Figure 1. Network architecture of the proposed PMBANet. To better present the whole framework and implementation details, different colored rectangles are
used to represent different stages and different operations in each stage.
Results

Figure 2. Visual comparison for recovered depth maps from 8x downsampling and noisy degradation on two examples (Books, Reindeer).

Figure 3. Generalization on MPI dataset (8x cases on Alley 1-48, Ambush 4-12)

Figure 4. Visualization of intermediate feature maps from all the branches in PMBANet. For clearly presenting the feature extraction process progressively,
we increase the MPA blocks up to K = 5.
Citation
Xinchen Ye, Baoli Sun, Zhihui Wang*, Jingyu Yang, Rui Xu, Haojie Li, Baopu Li, PMBANet: Progressive Multi-Branch Aggregation Network for Scene Depth Super-Resolution, IEEE Trans. Image Processing, 29:7427-7442, 2020.
@article{Ye2020tip,
author = {Xinchen Ye, Baoli Sun, Zhihui Wang, Jingyu Yang, Rui Xu, Haojie Li, Baopu Li},
title = {PMBANet: Progressive Multi-Branch Aggregation Network for Scene Depth Super-Resolution},
booktitle = {IEEE Trans. Image Processing (TIP)},
year={2020}, volume={29}, pages={7427-7442},
}
Depth Super-Resolution via Deep Controllable Slicing Network
Xinchen Ye1*, Baoli Sun1, Zhihui Wang*1, Jingyu Yang2, Rui Xu1, Haojie Li1, Baopu Li3
1 Dalian University of Technology, 2 Tianjin University, 3 Baidu Research, USA
* Corresponding author
Paper: ![]() DepthSlice.pdf
DepthSlice.pdf
Abstract
Due to the imaging limitation of depth sensors, high-resolution (HR) depth maps are often difficult to be acquired directly, thus effective depth super-resolution (DSR) algorithms are needed to generate HR output from its low-resolution (LR) counterpart. Previous methods treat all depth regions equally without considering different extents of degradation at region-level, and regard DSR under different scales as independent tasks without considering the modeling of different scales, which impede further performance improvement and practical use of DSR. To alleviate these problems, we propose a deep controllable slicing network from a novel perspective. Specifically, our model is to learn a set of slicing branches in a divide-and-conquer manner, parameterized by a distance-aware weighting scheme to adaptively aggregate different depths in an ensemble. Each branch that specifies a depth slice (e.g., the region in some depth range) tends to yield accurate depth recovery. Meanwhile, a scale-controllable module that extracts depth features under different scales is proposed and inserted into the front of slicing network, and enables finely-grained control of the depth restoration results of slicing network with a scale hyper-parameter. Extensive experiments on synthetic and real-world benchmark datasets demonstrate that our method achieves superior performance.
Method

Figure 1. Overview of the network architecture. SCM is to realize DSR with different downscaling factors in an unified model, which allows to finely-grained control the depth restoration results by using a scale parameter, while DSM aims to learn a set of slicing branches in a divide-and-conquer manner, parameterized by a distance-aware weighting scheme to adaptively aggregate all the branches in the ensemble.

Figure 2. Network architecture of our SCM. GB aims to extract the common features from the input, while SB takes the given scale parameter and its corresponding LR depth map as input, then generates specialized features to adaptively tune the features of GB through FB in a linear fusion fashion.
Results

Figure 3. Visual comparison for recovered depth maps from ×8 downsampling on NYU v2 dataset.

Figure 4. Visual comparison of ×8 (𝛾𝑖𝑛 = 3) upsampling results at different 𝛾𝑖𝑛 vaules.

Figure 5. Visualization of the weighting masks.
Citation
Xinchen Ye*, Baoli Sun, Zhihui Wang, Jingyu Yang, Rui Xu, Haojie Li, Baopu Li, Depth Super-Resolution via Deep Controllable Slicing Network, ACM International Conference on Multimedia (ACMMM), 2020, Seattle, USA.
@article{Ye2020acmmm,
author = {Xinchen Ye, Baoli Sun, Zhihui Wang, Jingyu Yang, Rui Xu, Haojie Li, Baopu Li},
title = {Depth Super-Resolution via Deep Controllable Slicing Network},
booktitle = {ACM International Conference on Multimedia (ACMMM)},
year={2020},
}
Deep Joint Depth Estimation and Color Correction from Monocular Underwater
Images based on Unsupervised Adaptation Networks
Xinchen Ye1, Zheng Li1, Baoli Sun1, Zhihui Wang*1, Rui Xu1, Haojie Li1, Xin Fan1
1 Dalian University of Technology
* Corresponding author
Paper: ![]() Underwater DE CC.pdf
Underwater DE CC.pdf
Abstract
Degraded visibility and geometrical distortion typically make the underwater vision more intractable than open air vision, which impedes the development of underwater-related machine vision and robotic perception. Therefore, this paper addresses the problem of joint underwater depth estimation and color correction from monocular underwater images, which aims at enjoying the mutual benefits between these two related tasks from a multi-task perspective. Our core ideas lie in our new deep learning architecture. Due to the lack of effective underwater training data, and the weak generalization to the real-world underwater images trained on synthetic data, we consider the problem from a novel perspective of style-level and feature-level adaptation, and propose an unsupervised adaptation network to deal with the joint learning problem. Specifically, a style adaptation network (SAN) is first proposed to learn a style-level transformation to adapt in-air images to the style of underwater domain. Then, we formulate a task network (TN) to jointly estimate the scene depth and correct the color from a single underwater image by learning domain-invariant representations. The whole framework can be trained end-to-end in an adversarial learning manner. Extensive experiments are conducted under air-to-water domain adaptation settings. We show that the proposed method performs favorably against state-of-the-art methods in both depth estimation and color correction tasks.
Method

Fig. 1. Our whole network architecture for joint depth estimation and color correction. It consists of two networks, i.e., style adaptation network (SAN) and task network (TN). Domain adaptation is used in both networks to adapt for low-level appearance style and high-level feature representation, simultaneously. The whole framework can be trained end-to-end in an adversarial learning manner. The depth maps are colored with red for farther distance while blue for closer distance for easy observation.

Fig. 2. Our stacked conditional GANs architecture for joint depth estimation and color correction. Gc is sketched out briefly and the domain adaptation modules on both generators are omitted for saving space.
Results

Fig. 3. Training datasets: From left to right are real underwater images captured under three different light conditions (bluish, greenish, shallow), and in-air NYU dataset, respectively.

Fig. 4. Evaluation on SAN from the perspective of training details and rendering results. (a) and (b) show the loss curves of training process from WaterGAN and ours. (c-e) present three visual examples for clearly observing the rendering results. From top to bottom are the results from WaterGAN, ours, and the real underwater images, respectively.

Fig. 5. Qualitative comparison on real underwater images under different module configurations: (a)DESN or CCSN separately; (b) DESN + CCSN, (c) DESN with DA + CCSN, (d) DESN with DA + CCSN with DA, (e) DESN + CCSN with DA. The depth maps are colored with red for farther distance, while blue for closer distance. We use red rectangles to direct readers to focus on those specific areas to compare the difference under different cases.
Citation
Xinchen Ye; Zheng Li; Baoli Sun; Zhihui Wang*; Rui Xu; Haojie Li; Xin Fan; Deep Joint Depth Estimation and Color Correction from Monocular Underwater Images based on Unsupervised Adaptation Networks, IEEE Trans. Circuits and Systems for Video Technology, 30(11): 3995-4008, 2020.
@article{Ye2020tcsvt,
author = {Xinchen Ye; Zheng Li; Baoli Sun; Zhihui Wang; Rui Xu; Haojie Li; Xin Fan},
title = {Deep Joint Depth Estimation and Color Correction from Monocular Underwater Images based on Unsupervised Adaptation Networks},
booktitle = {IEEE Trans. Circuits and Systems for Video Technology (TCSVT)},
year={2020}, volume={30}, number={11} pages={3995-4008},
}
DPNet: Detail-Preserving Network for High Quality Monocular Depth Estimation
Xinchen Ye1*, Shude Chen1, Rui Xu1
1 Dalian University of Technology
* Corresponding author
Paper: ![]() PR2021.pdf
PR2021.pdf
Abstract
Existing monocular depth estimation methods are unsatisfactory due to the inaccurate inference of depth details and the loss of spatial information. In this paper, we present a novel detail-preserving network (DPNet), i.e., a dual-branch network architecture that fully addresses the above problems and facilitates the depth map inference. Specifically, in contextual branch (CB), we propose an effective and efficient nonlocal spatial attention module by introducing non-local filtering strategy to explicitly exploit the pixel relationship in spatial domain, which can bring significant promotion on depth details inference. Mean- while, we design a spatial branch (SB) to preserve the spatial information and generate high-resolution features from input color image. A refinement module (RM) is then proposed to fuse the heterogeneous features from both spatial and contextual branches to obtain a high quality depth map. Experimental results show that the proposed method outperforms SOTA methods on benchmark RGB-D datasets.
Index Terms— Depth Estimation, CNN, Depth Prediction, Depth Enhancement, Monocular
Method


Publications
[1] Xinchen Ye*, Shude Chen, Rui Xu, DPNet: Detail-Preserving Network for High Quality Monocular Depth Estimation, Pattern Recognition, 109:107578, 2021.
[2] Xiangyue Duan, Xinchen Ye*, Yang Li, Haojie Li, High Quality Depth Estimation from Monocular Images Based on Depth Prediction and Enhancement Sub-Networks. IEEE International Conference onMultimedia and Expo, ICME 2018, San Diego, USA. (CCF-B)
Unsupervised detail-preserving network for high quality monocular
depth estimation
Xinchen Ye1*, Mingliang Zhang1, Xin Fan1
1 Dalian University of Technology
* Corresponding author
Introduction
Monocular depth estimation is a challenging task and has many important applications including scene understanding and reconstruction, autonomous navigation and augmented reality. In the last few years, deep learning has achieved great success in predicting the depth map from a single-view color image. Early works mainly focus on supervised learning. It is generally known that ground truth annotations are usually sparse or not easy to be captured by depth-sensing equipment. To handle this issue, recent
unsupervised methods refer to depth estimation as a image reconstruction problem, where view synthesis is an effective supervised signal to train the network. Therefore, we also adopt this unsupervised technique in the proposed framework. We propose an unsupervised detail-preserving framework for monocular depth estimation to address two problems, i.e., inaccurate inference of depth details and loss of spatial information.
Index Terms— Unsupervised network, Monocular, Depth estimation, Detail-preserving
Method



Publications
[1] Mingliang Zhang; Xinchen Ye*; Xin Fan; Wei Zhong; Unsupervised Depth Estimation from Monocular Videos with Hybrid Geometric-refined Loss and Contextual Attention, Neurocomputing, 379: 250-261, 2020.
[2] Mingliang Zhang; Xinchen Ye*; Xin Fan; Unsupervised Detail-Preserving Network for High Quality Monocular Depth Estimation, Neurocomputing, 404:1-13, 2020.
[3] Xinchen Ye*, Mingliang Zhang, Xin Fan, Rui Xu, Juncheng Pu, Ruoke Yan, Cascaded Detail-Aware Network for Unsupervised Monocular Depth Estimation, ICME 2020, London, UK. (CCF-B)
[4] Xinchen Ye*, Mingliang Zhang, Rui Xu, Wei Zhong, Xin Fan, Unsupervised Monocular Depth Estimation based on Dual Attention Mechanism and Depth-Aware Loss. IEEE International Conference on Multimedia and Expo, ICME 2019, Shanghai, China. (CCF-B)A Sparsity-Promoting Image Decomposition Model for Depth Recovery
Xinchen Ye*1, Mingliang Zhang1, Jingyu Yang2, Xin Fan1, Fangfang Guo1
1 Dalian University of Technology 2Tianjin University
* Corresponding author
Abstract
This paper proposes a novel image decomposition model for scene depth recovery from low-quality depth measurements and its corresponding high resolution color image. Through our observation, the depth map mainly contains smooth regions separated by additive step discontinuities, and can be simulta- neously decomposed into a local smooth surface and an approximately piecewise constant component. Therefore, the proposed unified model combines the least square polynomial approximation (for smooth surface) and a sparsity-promoting prior (for piecewise constant) to better portray the 2D depth signal intrinsically. As we know, the representation of the piecewise constant signal in gradient domain is ex- tremely sparse. Previous researches using total variation filter based on L 1 -norm or L p -norm (0 < p < 1) are both sub-optimal when addressing the tradeoffbetween enhancing the sparsity and keeping the model convex. We propose a novel non-convex penalty based on Moreau envelope, which promotes the prior sparsity and simultaneously maintains the convexity of the whole model for each variable. We prove the convexity of the proposed model and give the convergence analysis of the algorithm. We also introduce an iterative reweighted strategy applied on the sparsity prior to deal with the depth-color inconsistent problem and to locate the depth boundaries. Moreover, we provide an accelerated algorithm to deal with the problem of non-uniform down-sampling when transforming the depth observation matrix into the Fourier domain for fast processing. Experimental results demonstrate that the proposed method can han- dle various types of depth degradation and achieve promising performance in terms of recovery accuracy and running time.
Index Terms—Image decomposition Depth recovery Depth discontinuities Depth cameras
Method


Publications
[1] Xinchen Ye*, Mingliang Zhang, Jingyu Yang, Xin Fan, Fangfang Guo, A Sparsity-Promoting Image Decomposition Model for Depth Recovery, Pattern Recognition, 107: 107506, 2020. (CCF-B, 中科院1区TOP)
[2] Xinchen Ye, Xiaolin Song and Jingyu Yang*. Depth Recovery via Decomposition of Polynomial and Piece-wise Constant Signals. Visual Communications and Image Processing, 2016, Chengdu, China.
Depth Upsampling based on Deep Edge-Aware Learning
Zhihui Wang1, Xinchen Ye*1, Baoli Sun1, Jingyu Yang2, Rui Xu1, Haojie Li1
1 Dalian University of Technology 2Tianjin University
* Corresponding author
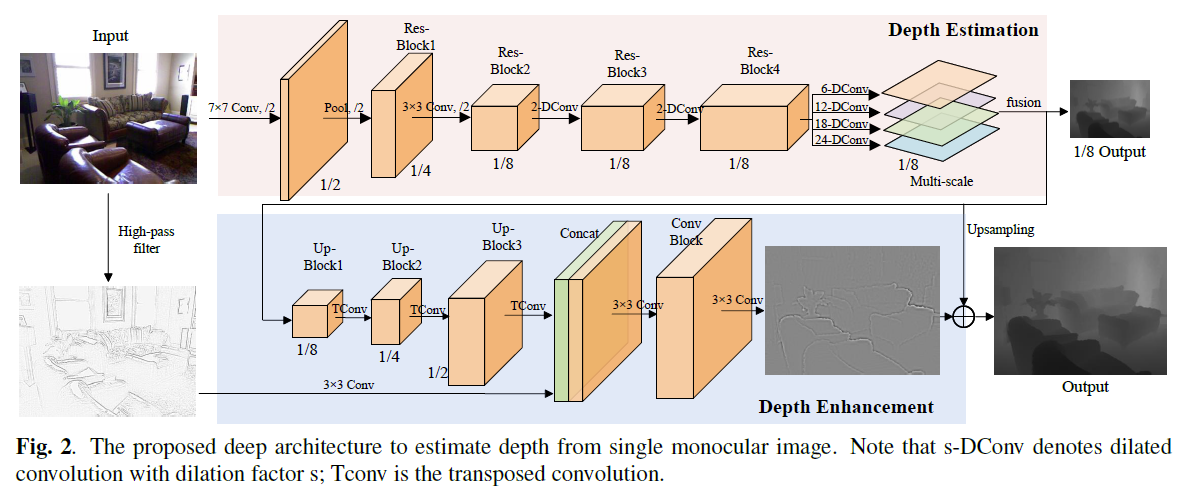
Abstract
In this paper, we propose a novel depth super-resolution framework with deep edge-inference network and edgeguided depth filling. We first construct a convolutional neural network (CNN) architecture to learn a binary map of depth edge location from low resolution depth map and corresponding color image. Then, a fast edge-guided depth filling strategy is proposed to interpolate the missing depth constrained by the acquired edges to prevent predicting across the depth boundaries. Experimental results show that our method outperforms the state-of-art methods in both the edges inference and the final results of depth super-resolution, and generalizes well for handling depth data captured in different scenes.
Index Terms— Super-resolution, depth image, edgeinference, edge-guided
Method
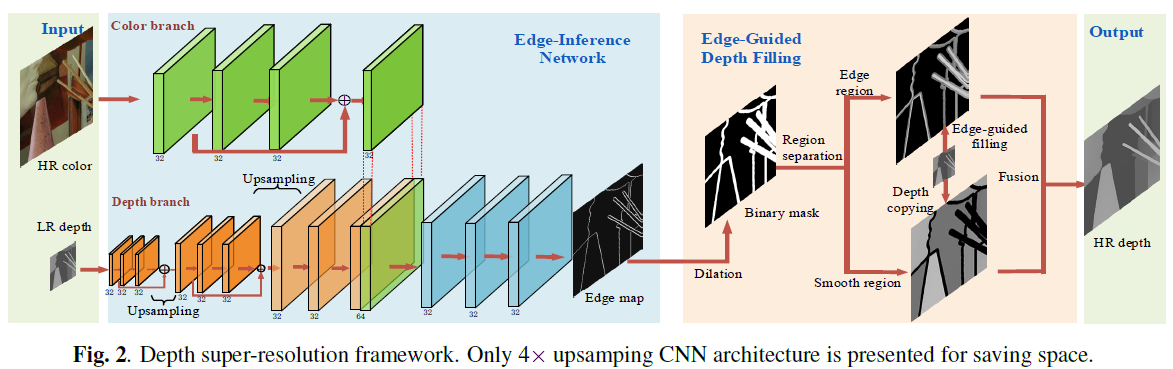
Publications
[1] Zhihui Wang; Xinchen Ye*; Baoli Sun; Jingyu Yang; Rui Xu, Haojie Li; Depth Upsampling based on Deep Edge-Aware Learning, Pattern Recognition, Pattern Recognition, 103: 107274, 2020.
[2] Xinchen Ye*, Xiangyue Duan, Haojie Li, Depth Super-Resolution With Deep Eedge-Inference Network and Edege-Guided Depth Filling. IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, Alberta, Canada.(CCF-B)
Retinal Vessel Segmetation
Rui Xu1, Xinchen Ye1
1 Dalian University of Technology
Abstract
Recently, the joint research team of Dalian University of Technology (DUT) and Risumeikan University (RU) has made important progress in the field of retinal vessel segmentation. Their paper “Boosting Connectivity in Retinal Vessel Segmentation via a Recursive Semantics-Guided Network” was accepted by Medical Image Computing and Computer Assisted Intervention Society (MICCAI), which is an international top academic corporation in the field of medical image analysis. This research result was jointly completed by DUT Associate Prof. Xu Rui, Associate Prof. Ye Xinchen, Graduate Student Liu Tiantian, and RU Prof. Chen Yanwei from College of Information Science and Engineering. In addition, it was funded by the DUT - RU Co-Research Center of Advanced ICT for Active Life.
Many deep learning based methods have been proposed for retinal vessel segmentation, however few of them focus on the connectivity of segmented vessels, which is quite important for a practical computer-aided diagnosis system on retinal images. In the paper, the research team proposes an efficient network to address this problem. A U-shape network is enhanced by introducing a semantics-guided module, which integrates the enriched semantics information to shallow layers for guiding the network to explore more powerful features. Besides, a recursive refinement iteratively applies the same network over the previous segmentation results for progressively boosting the performance while increasing no extra network parameters. The carefully designed recursive semantics-guided network has been extensively evaluated on several public datasets. Experimental results have shown the efficiency of the proposed method.

Related Research Results of Retinal Vessel Segmentation:
[1] Rui Xu, Guiliang Jiang, Xinchen Ye*, Yen-Wei Chen, Retinal Vessel Segmentation via Multiscaled Deep Guidance, Pacific Rim Conference on Multimedia 2018 (PCM 2018), Hefei, China, September 21-22, 2018.
[2] Rui Xu, Xinchen Ye*, Guiliang Jiang, Tiantian Liu, Liang Li, Satoshi Tanaka, Retinal Vessel Segmentation via a Semantics and Multi-Scale Aggregation Network, IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2020), Virtual Barcelona, May 4-8, 2020.
[3] Rui Xu, Tiantian Liu, Xinchen Ye*, Yen-Wei Chen, Boosting Connectivity in Retinal Vessel Segmentation via a Recursive Semantics-Guided Network, International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2020), accepted. (arXiv Version : https://arxiv.org/abs/2004.12776)
[4] Rui Xu, Tiantian Liu, Xinchen Ye*, Fei Liu, Lin Lin, Liang Li, Satoshi Tanaka, Yen Wei Chen, Joint Extraction of Retinal Vessels and Centerlines Based on Deep Semantics and Multi-Scaled Cross-Task Aggregation, IEEE Journal of Biomedical and Health Informatics, 10.1109/JBHI.2020.3044957, 2021 (中科院1区TOP)
DUT - RU Co-Research Center of Advanced ICT for Active Life
It was established on the development zone campus of DUT in June, 2018. It is an achievement of international cooperation between DUT and RU and mainly conducted by DUT-RU International School of Information Science & Engineering. The Co-Research Center has set up a platform for international research cooperation and communication in the cross research field of health care and information science, and established the “International Research Exchange and Cooperation Promotion Project”, which funds relevant researchers to carry out in-depth international research cooperation in ICT (information computing technology), medical and health fields.
DRM-SLAM: Towards Dense Reconstruction of Monocular SLAM with Scene Depth Fusion
Xinchen Ye*, Xiang Ji, Baoli Sun, Shenglun Chen, Zhihui Wang, Haojie Li
Dalian University of Technology
* Corresponding author
Abstract
Real-time monocular visual SLAM approaches relying on building sparse correspondences between two or multiple views of the scene, are capable of accurately tracking camera pose and inferring structure of the environment. However, these methods have the common problem, i.e., the reconstructed 3D map is extremely sparse. Recently, convolutional neural network (CNN) is widely used for estimating scene depth from monocular color images. As we observe, sparse map-points generated from epipolar geometry are locally accurate, while CNN-inferred depth map contains high-level global context but generates blurry depth boundaries. Therefore, we propose a depth fusion framework to yield a dense monocular reconstruction that fully exploits the sparse depth samples and the CNN-inferred depth. Color key-frames are employed to guide the depth reconstruction process, avoiding smoothing over depth boundaries. Experimental results on benchmark datasets show the robustness and accuracy of our method.
Index Terms— Dense reconstruction, Visual SLAM, Monocular, Sparse map-point, Depth prediction.
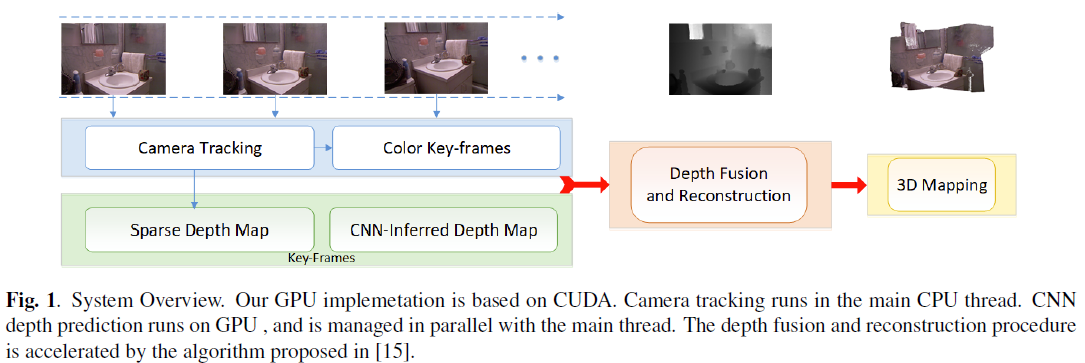
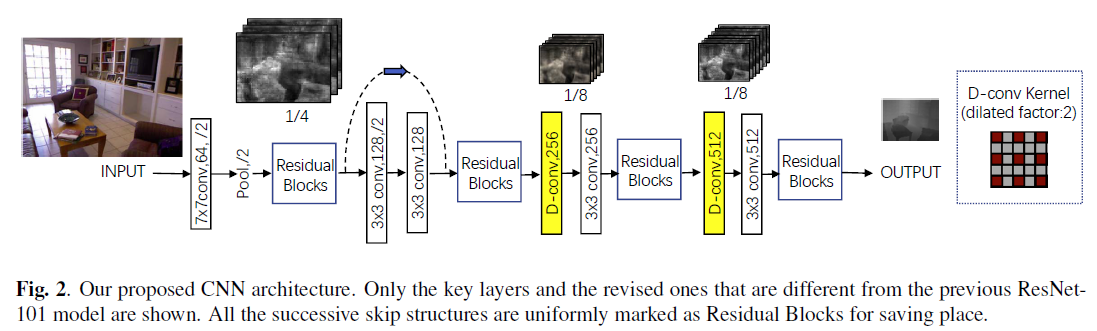
Publications
[1] Xinchen Ye*; Xiang Ji; Baoli Sun; Shenglun Chen; Zhihui Wang; Haojie Li; DRM-SLAM: Towards Dense Reconstruction of Monocular SLAM with Scene Depth Fusion, Neurocomputing, 396: 76-91, 2020.
[2] Xiang Ji, Xinchen Ye*, Hongcan Xu, Haojie Li, Dense Reconstruction from Monocular SLAM with Fusion of Sparse Map-Points and CNN-Inferred Depth. IEEE International Conference on Multimedia and Expo, ICME 2018, San Diego, USA. (CCF-B)
Global Autoregressive Depth Recovery via Non-Local Iterative Filtering
Jingyu Yang2, Xinchen Ye*1, Pascal Frossard3
1 Dalian University of Technology 2Tianjin University 3EPFL
* Corresponding author
Abstract
Existing depth sensing techniques have many shortcomings in terms of resolution, completeness, and accuracy. The performance of 3D broadcasting systems is therefore limited by the challenges of capturing high resolution depth data. In this paper, we present a novel framework for obtaining high-quality depth images and multi-view depth videos from simple acquisition systems. We first propose a single depth image recovery (ARSDIR) algorithm based on auto-regressive (AR) correlations. A fixed-point iteration algorithm under the global AR modeling is derived to efficiently solve the largescale quadratic programming. Each iteration is equivalent to a nonlocal filtering process with a residue feedback. Then, we extend our framework to an AR-based multi-view depth video recovery (ARMDVR) framework, where each depth map is recovered from low-quality measurements with the help of the corresponding color image, depth maps from neighboring views, and depth maps of temporally-adjacent frames. AR coefficients on nonlocal spatiotemporal neighborhoods in the algorithm are designed to improve the recovery performance. We further discuss the connections between our model and other methods like graph-based tools, and demonstrate that our algorithms enjoy the advantages of both global and local methods. Experimental results on both the Middleburry datasets and other captured datasets finally show that our method is able to improve the performances of depth images and multi-view depth videos recovery compared with state-of-the-art approaches.
Index Terms—Depth recovery, multi-view, auto regressive, nonlocal, iterative filtering
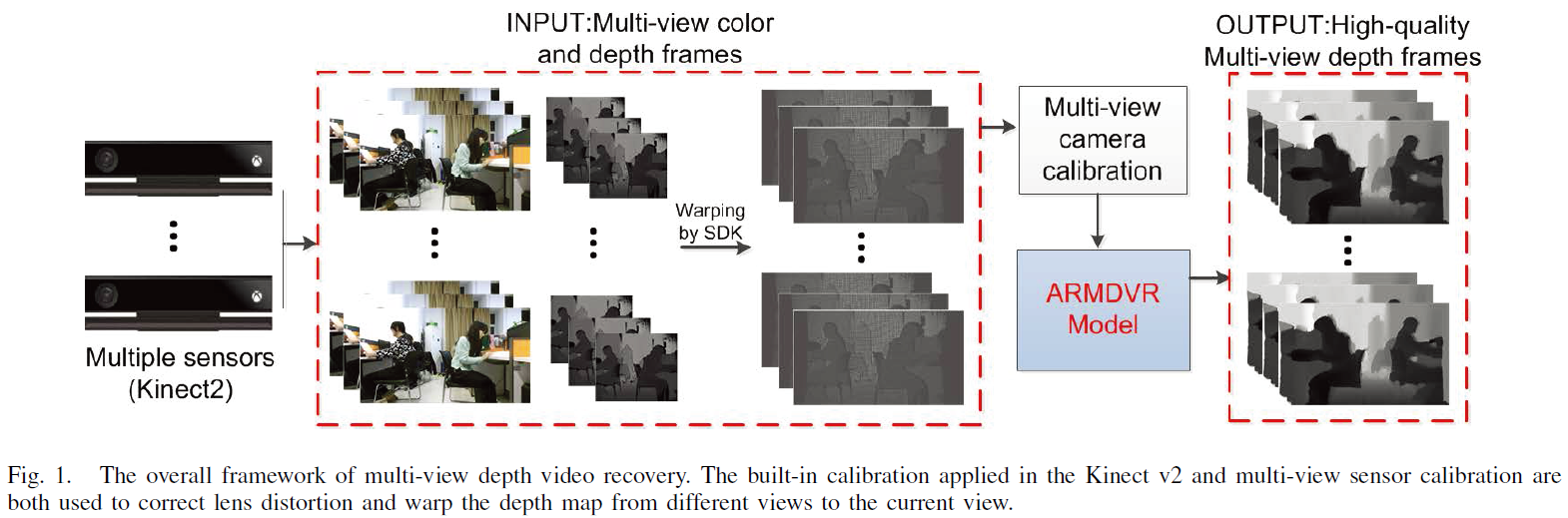
Publications
[1] Jingyu Yang, Xinchen Ye*, Global autoregressive depth recovery via non-local iterative filtering. IEEE Transactions on Broadcasting, 65(1), 123-137, 2019.(中科院2区)
[2] Jinghui Bai, Jingyu Yang* and Xinchen Ye. Depth Refinement for Binocular Kinect RGB-D Cameras. Visual Communications and Image Processing, 2016, Chengdu, China.
Color-Guided Depth Recovery From RGB-D Data Using an Adaptive Autoregressive Model
Jingyu Yang, Xinchen Ye, Kun Li, Chunping Hou, and Yao Wang
http://cs.tju.edu.cn/faculty/likun/projects/depth_recovery/index.htm
Abstract
This paper proposes an adaptive color-guided auto-regressive (AR) model for high quality depth recovery from low quality measurements captured by depth cameras. We observe and verify that the AR model tightly fits depth maps of generic scenes. The depth recovery task is formulated into a minimization of AR prediction errors subject to measurement consistency. The AR predictor for each pixel is constructed according to both the local correlation in the initial depth map and the nonlocal similarity in the accompanied high quality color image. We analyze the stability of our method from a linear system point of view, and design a parameter adaptation scheme to achieve stable and accurate depth recovery. Quantitative and qualitative results show that our method outperforms four state-of-the-art schemes. Being able to handle various types of depth degradations, the proposed method is versatile for mainstream depth sensors, ToF camera and Kinect, as demonstrated by experiments on real systems.
Keywords: Depth recovery (upsampling, inpainting, denoising), autoregressive model, RGB-D camera (ToF camera, Kinect)

Downloads
Datasets: Various datasets can be downloaded via the links attached to the following tables and figures.
Source code: download here
The degraded datasets in Table 1 can be obtained by downsampling the original high-resolution Middlebury datasets.
Publications
[1] Jingyu Yang, Xinchen Ye, Kun Li, Chunping Hou, Yao Wang, “Color-Guided Depth Recovery From RGB-D Data Using an Adaptive Autoregressive Model”, IEEE Transactions on Image Processing, vol. 23, no. 8, pp. 3443-3458, 2014. [pdf][bib]
[2] Jingyu Yang, Xinchen Ye, Kun Li, and Chunping Hou, “Depth recovery using an adaptive color-guided auto-regressive model”, European Conference on Computer Vision (ECCV), October 7-13, 2012, Firenze, Italy. [pdf] [bib]
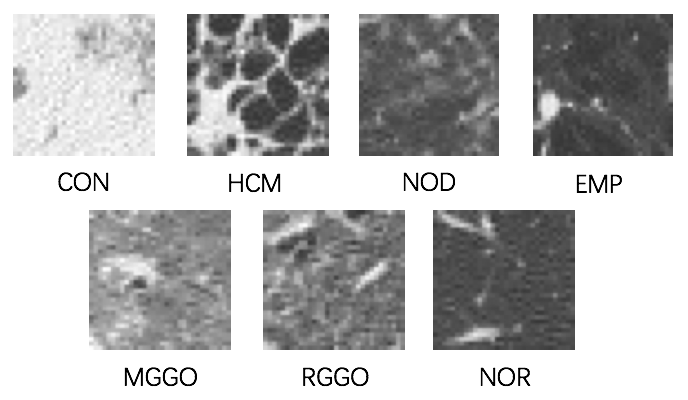
Pulmonary Textures Classification Using A Deep Neural Network with Appearence and Geometry Cues
Rui Xu, Zhen Cong, Xinchen Ye*
Dalian University of Technology
* Corresponding author
ABSTRACT
Classification of pulmonary textures on CT images is essential for the development of a computer-aided diagnosis system of diffuse lung diseases. In this paper, we propose a novel method to classify pulmonary textures by using a deep neural network, which can make full use of appearance and geometry cues of textures via a dual-branch architecture. The proposed method has been evaluated by a dataset that includes seven kinds of typical pulmonary textures. Experimental results show that our method outperforms the state-of-the-art methods including feature engineering based method and convolutional neural network based method.
Index Terms— residual network, pulmonary texture, Hessian matrix, CAD, CT
METHOD

PUBLICATIONS
[1] Rui Xu, Zhen Cong, Xinchen Ye*, Pulmonary Textures Classification via a Multi-Scale Attention Network, IEEE journal of Biomedical and Health Informatics, 24(7), 2041-2052, 2020.
[2] Rui Xu, Zhen Cong, Xinchen Ye*, Pulmonary Textures Classification Using A Deep Neural Network with Appearence and Geometry Cues, IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, Alberta, Canada.(CCF-B)
[3] Rui Xu, Jiao Pan, Xinchen Ye, S. Kido and S. Tanaka, "A pilot study to utilize a deep convolutional network to segment lungs with complex opacities," IEEE Chinese Automation Congress (CAC), Jinan, 2017, pp. 3291-3295.
